papers_we_read
Learning Video Representations from Large Language Models
Yue Zhao, Ishan Misra, Philipp Krähenbüh, Rohit Girdhar, Facebook AI Research- Meta AI, University of Texas, Austin 2022
Summary
The approach proposed in this paper, LaViLa (Language-model augmented Video-Language), uses Large Language Models that are repurposed to be conditioned on visual input and then fine tunes it to create automatic visual narrators that generate dense textual descriptions of videos. These generated descriptions are then used to contrastively train Dual Encoder models with learned video text embeddings, which outperforms existing models.
Contributions
- Since the model uses captions generated by an LLM, we can train the Dual Encoder effectively even with a very small fraction of ground-truth dataset. This is highly beneficial since the amount of readily available densely annotated video clips are very less.
- It provides a very strong alignment between the visual input and generated text.
- It can also expand annotations when they are provided very sparsely, or are not able to capture all details of activities occuring in the video frame.
Method

- The method LaViLa uses 2 LLM’s: a NARRATOR and a REPHRASER for pseudo-text generation. These are pretrained on english words, and are fine-tuned on visual embeddings.
- The Narrator architecture uses a frozen pre-trained LLM, and adds cross-attention modules having text tokens and the visual embeddings as input.
- The Rephraser paraphrases the output generated by Narrator by replacing synonyms or changing word order etc.
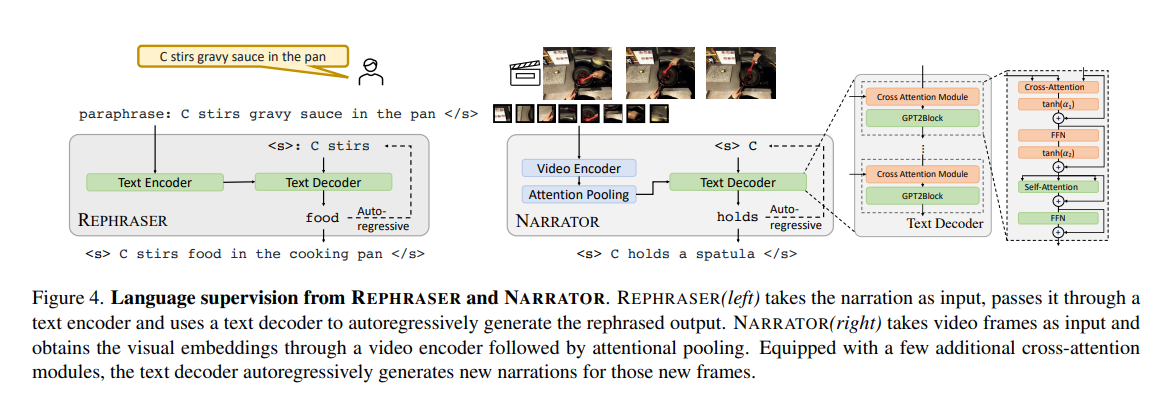
- The pseudo-captions generated by the Narrator and Rephraser, alongwith the ground truth video-text pairs are then used to train the DUAL ENCODER. It uses contrastive losses such as CLIP, InfoNCE for the same.
Results
LaViLa outperforms the previous state-of-the-art video-language pretraining methods on different datasets such as EK100 MIR, Charades-Ego, EGTEA etc.
The evaluation is done through several protocols, and the approach outperforms the previous SOTA in all cases.
- In Zero-Shot protocol, the model is applied to a new set of downstream validation datasets.
[ The two different numbers are obtained on using two different number of frames as input (4-frame and 16-frame respectively) ].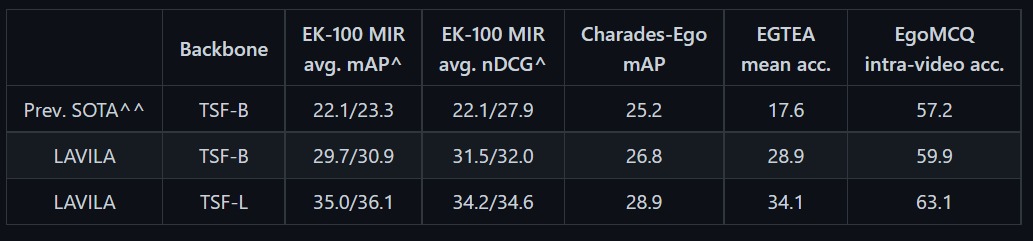
- In Fine-Tuned protocol, the model is end-to-end fine-tuned on the training split of the target downstream datasets.
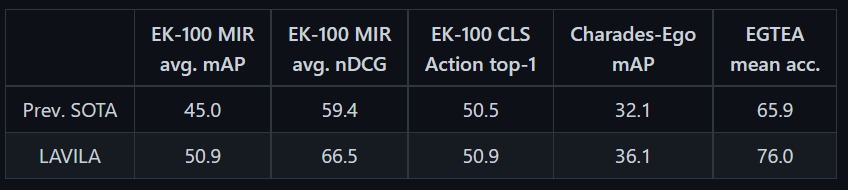
Two-Cents
- The existing state-of-the-art models for video-language representation lack efficient utilization of a very crucial knowledge base of pretrained LLM’s, that include language intricacies such as conversational ability, factual knowledge, grammatical relations etc. which is well implemented in this approach.
- Improvement of the output generated by Narrator for third person views by training on more relevant datasets and experimentation with different LLM’s can be some future areas of work.
Resources
- Paper: https://facebookresearch.github.io/LaViLa/
- Implementation : https://colab.research.google.com/drive/1gHWiEWywIotRivYQTR-8NQ6GJC7sJUe4
- Demo: https://huggingface.co/spaces/nateraw/lavila