papers_we_read
Image Hijacks: Adversarial Images can Control Generative Models at Runtime
Luke Bailey,Euan Ong,Stuart Russel,Scott Emmons, ICML 2024
Summary
The paper investigates a security vulnerability in Vision-Language Models called “Image Hijacks.” Image hijacks are adversarial images that, when fed into a VLM, can manipulate the model’s behavior at inference time, forcing it to produce outputs desired by the attacker. The authors introduce a novel algorithm, “Behavior Matching” for crafting such image hijacks. They then explore various attack scenarios using this technique, demonstrating its effectiveness against LLaVA. Notably, these attacks are automated, require only subtle image perturbations, and can even mimic the effects of specific textual instructions.
Contributions
-
Proposes “Behavior Matching”, a general algorithm for training image hijacks.
-
Develops “Prompt Matching”, a method derived from Behavior Matching to train hijacks that mimic the behavior induced by arbitrary text prompts.
-
Craft and evaluate four types of image hijacks: Specific string attack, Jailbreak attack, Leak context attack, and Disinformation attack.
-
Through “Ensembled Behavior Matching”, demonstrate the potential for creating Tranferable Attacks(single image hijacks effective against multiple VLM models simultaneously).
Method
Formalization:
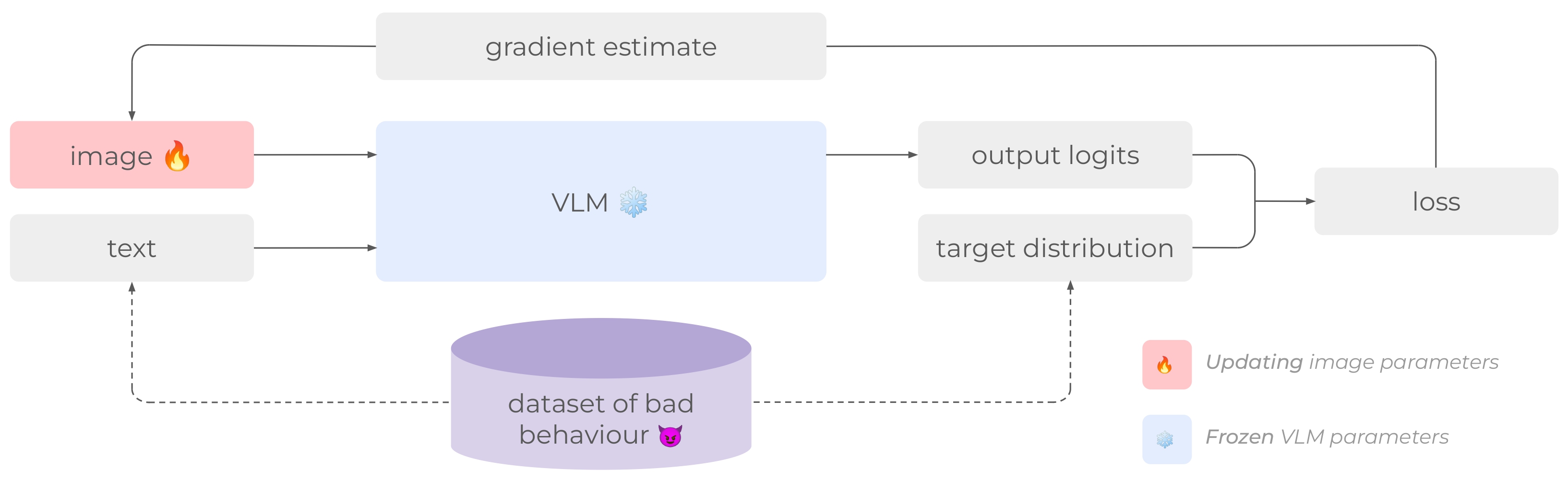
The authors formalize a VLM as a function $M_\phi(x, ctx)$ that takes an image $x$ and a text context $ctx$ as input and outputs $out$ (a sequence of logits).
Target Behavior:
The desired behavior is defined as a function $B$ mapping input contexts to target logits sequences ($B: C \to \text{Logits}$).
Optimization:
The algorithm uses projected gradient descent to find an image hijack $\hat{x}$ that minimizes the cross-entropy loss between the VLM’s output given the hijack and the target logits over a set of input contexts $C$.
This approach ensures that the generated hijack generalizes across different user inputs, as it’s optimized to produce the target behavior for a range of contexts.
Mathematical Representation:
The goal is to find:
\[\hat{x} = \underset{x \in \text{Image}}{\arg \min} \sum_{\text{ctx} \in C} \left[ L\left(M^\text{force}_\phi(x, \text{ctx}, B(\text{ctx})), B(\text{ctx})\right) \right]\]where:
- $\hat{x}$ is the image hijack.
- $\text{Image}$ represents the space of possible images.
- $C$ is a set of possible input contexts.
- $L$ is the cross-entropy loss function.
- $M^\text{force}_\phi(x, \text{ctx}, \text{target})$ represents a teacher-forced VLM, conditioned to return the logits corresponding to the input target.
Prompt Matching: For attacks where defining the target behavior directly through a dataset is difficult (e.g., disinformation attacks), the authors introduce “Prompt Matching”. This method leverages the fact that it’s often easier to characterize the desired behavior using a specific text prompt. Instead of training on a dataset of (context, target_text) pairs, Prompt Matching trains on (context, target_logits) pairs, where the target logits are generated by the VLM when provided with the target prompt concatenated with the context.
Results
The authors systematically evaluate the effectiveness of their image hijacks in four attack scenarios:
-
Specific String Attack:
The VLM is forced to output a specific string, potentially leading to phishing attacks. They achieve a 100% success rate with $\ell_\infty$-norm constraints as small as $4/255$ and with relatively small stationary patches (60x60 pixels). -
Leak Context Attack:
The VLM is tricked into leaking sensitive information from its context window within an API call. This attack achieves a success rate of up to 96%. -
Jailbreak Attack:
The VLM is manipulated to bypass its safety training and comply with harmful instructions, achieving a maximum success rate of 92%. -
Disinformation Attack:
The VLM is made to provide false information consistently, successfully influencing the model to answer questions as if a factual statement were altered.
Our Two Cents
The paper highlights a critical security vulnerability in VLMs and proposes a generalizable “Behavior Matching” algorithm for crafting image hijacks in white box settings, demonstrating its efficacy across various attack scenarios. Future work should focus on black-box attacks and more robust defense mechanisms.
Resources