papers_we_read
Human-level play in the game of Diplomacy by combining language models with strategic reasoning
Meta Fundamental AI Research Diplomacy Team (FAIR), Antin Bakhtun, Noam Brown, Emily Dinan Science Journal 2022
Summary
Unlike competitive games like Chess and Go, which computers have mastered through self-play, the game Diplomacy has been a different challenge because it involves major human elements
like cooperation and understanding other players’ motivations. CICERO is the first AI agent to achieve human-level performance in Diplomacy.
CICERO uses a language model integrated with a strategy model by understanding conversations happening during the game and generating dialogue to achieve its objectives.
Diplomacy
In Diplomacy, seven players conduct private natural language negotiations to coordinate their actions to cooperate and compete. Its main distinctions from most board wargames are its negotiation phases. Social interaction and interpersonal skills make up an essential part of the play. The rules that simulate combat are strategic, abstract, and simple—not tactical, realistic, or complex—as this is a diplomatic simulation game, not a military one.
Contributions
- Diplomacy is unique because it requires building trust with others in an environment that encourages players not to trust anyone.
- Cicero couples a dialogue module with a strategic reasoning engine.
- Cicero uses the dialogue and state of the board as a starting point for a planning algorithm that uses RL-trained models to predict the possible human actions of each participant.
Method
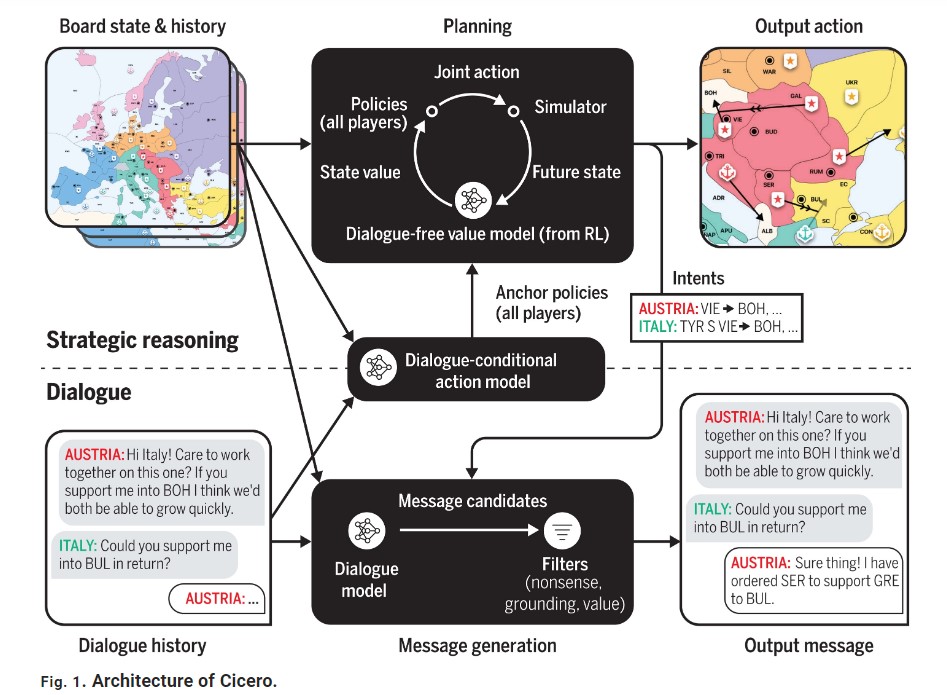
- In addition to the classic RL principles, Cicero uses anchor policies governed by a Dialogue-conditional action model, which act as behaviour cloning policies.
In the absence of these anchor policies, the actions of our model become ‘non-human’, where the model could devise an optimal strategy but which would not fit a human environment. - The model defines a message to have intent z if z is the most likely set of actions the sender and the recipient will take.
- The model uses piKL algorithm to predict player policies.
\({U_i(π_i,π_{−i})=u_i(π_i,π_{−i})−λD_{KL}(π_i∥τ_i)}\)
where π_i is the policy of player i, π_{−i} the policy of all players other than i, λ is the anchor strength. - The parameter λ is interesting in that it is the measure of the “human-ness” of a policy, and the model uses the high value of λ when predicting players’ moves and a lower weight while making its own.
Results
- Across 40 games of an anonymous online Diplomacy league, Cicero achieved more than double the average score of the human players and ranked in the top 10% of participants who played more than one game.
- Comparisons with the baselines.
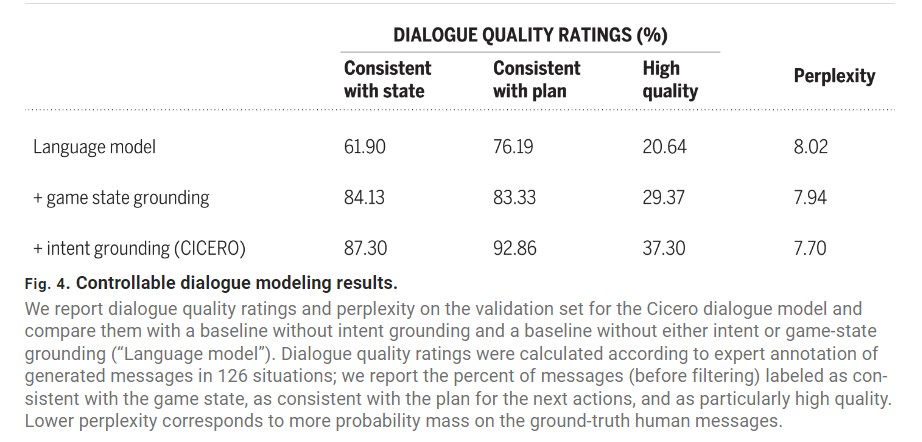
Two-Cents
- The model is an excellent development in areas with a cooperative element, and the authors also say that Cicero is not about Diplomacy; it has been used as a benchmark.
- The dialogue module and the strategic reasoning engine of the model are more disjoint than we would hope, and it would be interesting to see that improve in the future.
- The λ parameter does show us that even in Diplomacy, the more strategic policies are better than “human-like” policies, which tend to include human emotions.
Resources
Paper: https://www.science.org/doi/10.1126/science.ade9097
Blog by Meta AI: https://ai.facebook.com/blog/cicero-ai-negotiates-persuades-and-cooperates-with-people/