papers_we_read
Big Bird: Transformers for Longer Sequences
Manzil Zaheer, et al. , NeurIPS 2020
Summary
The paper presents BIGBIRD, a Transformer-based model designed to overcome the quadratic dependency on sequence length characteristic of such models. BIGBIRD introduces a sparse attention mechanism, reducing this dependency to linear. The model maintains all the theoretical properties of a full Transformer, while improving the ability to handle longer sequences due to its elaborate design, thus improving performance on various NLP tasks and expanding its applicability to DNA sequence representation.
Contributions
-
Theoretical Advancements in Transformer Model: The BigBird model satisfies all known theoretical properties of a full transformer. Particularly, the addition of extra tokens allows it to express all continuous sequence-to-sequence functions with only O(n) inner products. Furthermore, under standard precision assumptions, BigBird proves to be Turing complete.
-
Empirical Benefits Proven on Various NLP tasks: BigBird has been demonstrated to benefit a variety of NLP tasks due to its modeling of extended context. It has delivered state-of-the-art results on different datasets for tasks such as question answering and document summarization, displaying an impressive empirical improvement over prior methods.
-
Innovative Application in Genomics: A pioneering application of attention-based models is introduced where long contexts are beneficial. BigBird is utilized for extracting contextual representations of genomics sequences such as DNA. With extensive masked Language Model (LM) pretraining, BigBird has shown improved performance on downstream tasks like promoter-region and chromatin profile prediction, hinting at its promising applicability beyond the realm of traditional NLP tasks
Method
BIGBIRD uses a generalized attention mechanism in each layer of the Transformer operating on an input sequence. This sparse attention mechanism is implemented as a sparsification of a directed graph, where each query attends over r randomly chosen keys. Changing the attention mechanism to a sparse model introduces a cost, and any sufficiently sparse mechanism will require more layers. BIGBIRD resolves this complexity by introducing global tokens and utilizing a sliding window to capture local structures, effectively constructing a sparse random graph which has logarithmic shortest path between nodes.
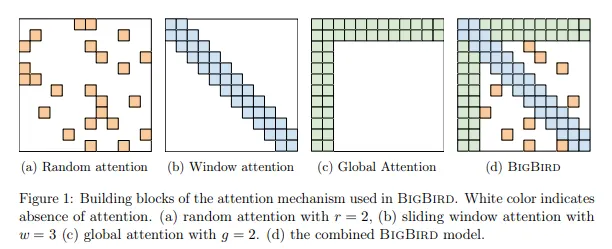
Results
BIGBIRD demonstrates significant improvement on various NLP tasks on different datasets. In pretraining, it outperforms models like RoBERTa and Longformer. In question answering and document classification tasks, especially on long documents, BIGBIRD’s performance surpasses other models. In generative tasks like document summarization, it was found that modeling longer context leads to significant improvement. In genomics, the new model exhibits high performance in tasks related to DNA sequence interpretation, thereby demonstrating the model’s broad applicability beyond NLP.
Two Cents
While it’s acknowledged that sparse attention mechanisms do not serve as a universal replacement for dense attention mechanisms, and that there is a cost involved in switching to a sparse attention mechanism, the potential of the BigBird model in transforming the field of Natural Language Processing (NLP) is undeniable. Despite these trade-offs, the revolutionizing capability of BigBird, particularly in handling longer sequence lengths and its successful application across various NLP tasks, signify substantial progress and have the potential for significant, far-reaching impacts in NLP.
Resources
- Link to Paper : https://arxiv.org/pdf/2007.14062.pdf
- Other resources and blogs : https://www.analyticsvidhya.com/blog/2022/11/an-introduction-to-bigbird/ https://towardsdatascience.com/understanding-bigbird-is-it-another-big-milestone-in-nlp-e7546b2c9643
- Code : https://github.com/google-research/bigbird